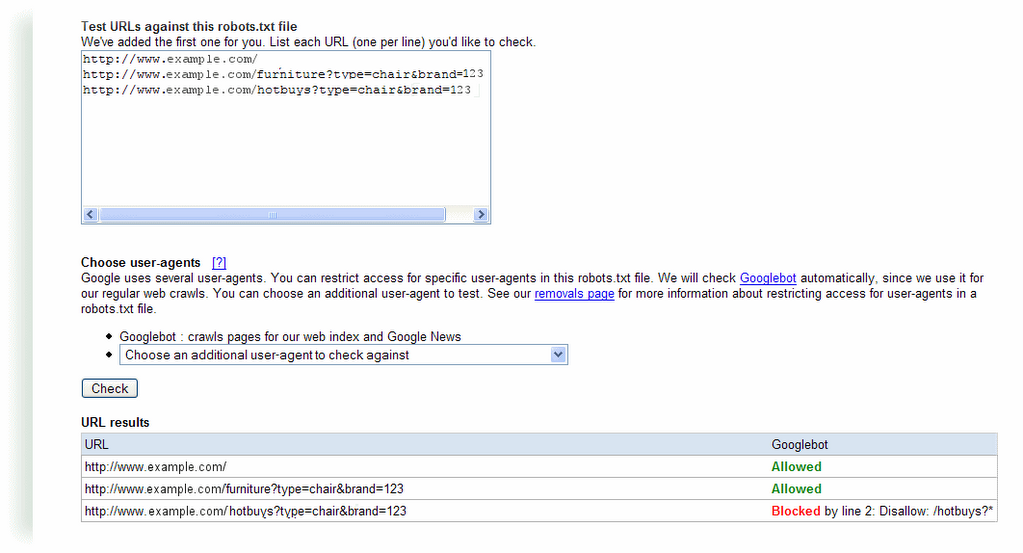
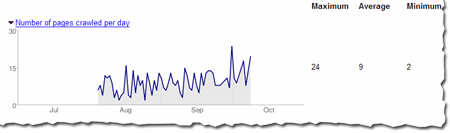
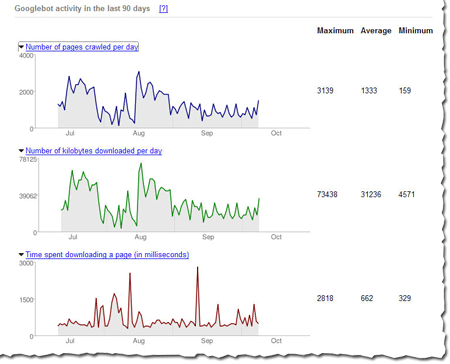
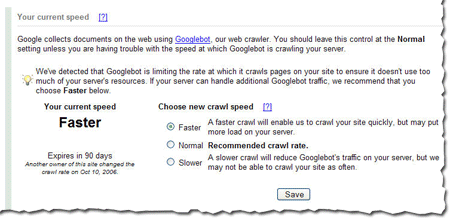
Webmaster level: intermediate
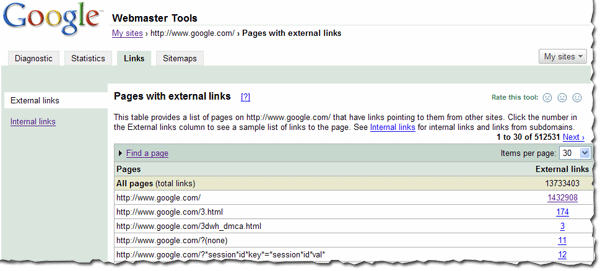
In recent years, our free Webmaster Tools product has provided roughly 100,000 backlinks when you click the "Download more sample links" button. Until now, we've selected those links primarily by lexicographical order. That meant that for some sites, you didn't get as complete of a picture of the site's backlinks because the link data skewed toward the beginning of the alphabet.
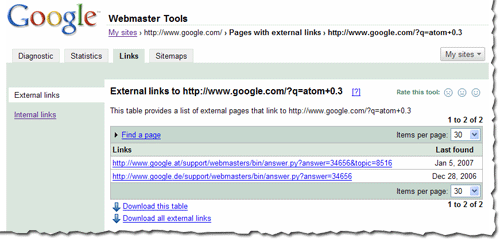
Based on feedback from the webmaster community, we're improving how we select these backlinks to give sites a fuller picture of their backlink profile. The most significant improvement you'll see is that most of the links are now sampled uniformly from the full spectrum of backlinks rather than alphabetically. You're also more likely to get example links from different top-level domains (TLDs) as well as from different domain names. The new links you see will still be sorted alphabetically.
Starting soon, when you download your data, you'll notice a much broader, more diverse cross-section of links. Site owners looking for insights into who recommends their content will now have a better overview of those links, and those working on cleaning up any bad linking practices will find it easier to see where to spend their time and effort.
Thanks for the feedback, and we'll keep working to provide helpful data and resources in Webmaster Tools. As always, please ask in our forums if you have any questions.
In recent years, our free Webmaster Tools product has provided roughly 100,000 backlinks when you click the "Download more sample links" button. Until now, we've selected those links primarily by lexicographical order. That meant that for some sites, you didn't get as complete of a picture of the site's backlinks because the link data skewed toward the beginning of the alphabet.
Based on feedback from the webmaster community, we're improving how we select these backlinks to give sites a fuller picture of their backlink profile. The most significant improvement you'll see is that most of the links are now sampled uniformly from the full spectrum of backlinks rather than alphabetically. You're also more likely to get example links from different top-level domains (TLDs) as well as from different domain names. The new links you see will still be sorted alphabetically.
Starting soon, when you download your data, you'll notice a much broader, more diverse cross-section of links. Site owners looking for insights into who recommends their content will now have a better overview of those links, and those working on cleaning up any bad linking practices will find it easier to see where to spend their time and effort.
Thanks for the feedback, and we'll keep working to provide helpful data and resources in Webmaster Tools. As always, please ask in our forums if you have any questions.