Last Friday afternoon, I was able to catch the end of the Blog Business Summit in Seattle. At the session called "Blogging and SEO Strategies," John Battelle brought up a good point. He said that as a writer, he doesn't want to have to think about all of this search engine optimization stuff. Dave Taylor had just been talking about order of words in title tags and keyword density and using hyphens rather than underscores in URLs.
We agree, which is why you'll find that the main point in our webmaster guidelines is to make sites for visitors, not for search engines. Visitor-friendly design makes for search engine friendly design as well. The team at Google webmaster central talks a lot with site owners who care a lot about the details of how Google crawls and indexes sites (hyphens and underscores included), but many site owners out there are just concerned with building great sites. The good news is that the guidelines and tips about how Google crawls and indexes sites come down to wanting great content for our search results.
In the spirit of John Battelle's point, here's a recap of some quick tips for ensuring your site is friendly for visitors.
Make good use of page titles
This is true of the main heading on the page itself, but is also true of the title that appears in the browser's title bar.

Whenever possible, ensure each page has a unique title that describes the page well. For instance, if your site is for your store "Buffy's House of Sofas", a visitor may want to bookmark your home page and the order page for your red, fluffy sofa. If all of your pages have the same title: "Wecome to my site!", then a visitor will have trouble finding your site again in the bookmarks. However, if your home page has the title "Buffy's House of Sofas" and your red sofa page has the title "Buffy's red fluffy sofa", then visitors can glance at the title to see what it's about and can easily find it in the bookmarks later. And if your visitors are anything like me, they may have several browser tabs open and appreciate descriptive titles for easier navigation.
This simple tip for visitors helps search engines too. Search engines index pages based on the words contained in them, and including descriptive titles helps search engines know what the pages are about. And search engines often use a page's title in the search results. "Welcome to my site" may not entice searchers to click on your site in the results quite so much as "Buffy's House of Sofas".
 Write with words
Write with words
Images, flash, and other multimedia make for pretty web pages, but make sure your core messages are in text or use ALT text to provide textual descriptions of your multimedia. This is great for search engines, which are based on text: searchers enter search queries as word, after all. But it's also great for visitors, who may have images or Flash turned off in their browsers or might be using screen readers or mobile devices. You can also provide HTML versions of your multimedia-based pages (if you do that, be sure to block the multimedia versions from being indexed using a robots.txt file).
Make sure the text you're talking about is in your content
Visitors may not read your web site linearly like they would a newspaper article or book. Visitors may follow links from elsewhere on the web to any of your pages. Make sure that they have context for any page they're on. On your order page, don't just write "order now!" Write something like "Order your fluffy red sofa now!" But write it for people who will be reading your site. Don't try to cram as many words in as possible, thinking search engines can index more words that way. Think of your visitors. What are they going to be searching for? Is your site full of industry jargon when they'll be searching for you with more informal words?
As I wrote in that guest post on Matt Cutts' blog when I talked about hyphens and underscores:
You know what your site’s about, so it may seem completely obvious to you when you look at your home page. But ask someone else to take a look and don’t tell them anything about the site. What do they think your site is about?
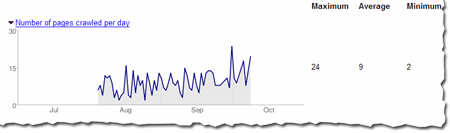
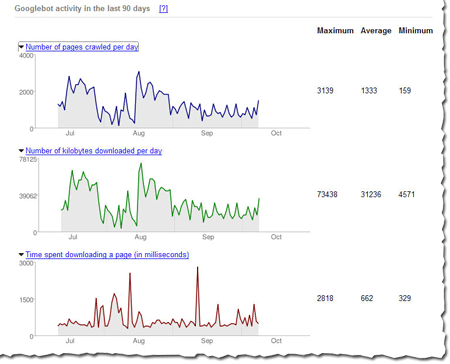
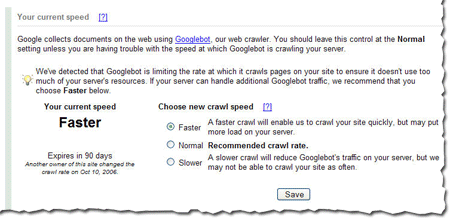
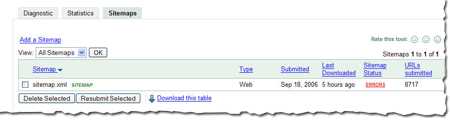
I know -- this post was supposed to be about writing content, not technical details. But visitors can't read your site if they can't access it. If the network is down or your server returns errors when someone tries to access the pages of your site, it's not just search engines who will have trouble. Fortunately, webmaster tools makes it easy. We'll let you know if we've had any trouble accessing any of the pages. We tell you the specific page we couldn't access and the exact error we got. These problems aren't always easy to fix, but we try to make them easy to find.
We agree, which is why you'll find that the main point in our webmaster guidelines is to make sites for visitors, not for search engines. Visitor-friendly design makes for search engine friendly design as well. The team at Google webmaster central talks a lot with site owners who care a lot about the details of how Google crawls and indexes sites (hyphens and underscores included), but many site owners out there are just concerned with building great sites. The good news is that the guidelines and tips about how Google crawls and indexes sites come down to wanting great content for our search results.
In the spirit of John Battelle's point, here's a recap of some quick tips for ensuring your site is friendly for visitors.
Make good use of page titles
This is true of the main heading on the page itself, but is also true of the title that appears in the browser's title bar.

Whenever possible, ensure each page has a unique title that describes the page well. For instance, if your site is for your store "Buffy's House of Sofas", a visitor may want to bookmark your home page and the order page for your red, fluffy sofa. If all of your pages have the same title: "Wecome to my site!", then a visitor will have trouble finding your site again in the bookmarks. However, if your home page has the title "Buffy's House of Sofas" and your red sofa page has the title "Buffy's red fluffy sofa", then visitors can glance at the title to see what it's about and can easily find it in the bookmarks later. And if your visitors are anything like me, they may have several browser tabs open and appreciate descriptive titles for easier navigation.
This simple tip for visitors helps search engines too. Search engines index pages based on the words contained in them, and including descriptive titles helps search engines know what the pages are about. And search engines often use a page's title in the search results. "Welcome to my site" may not entice searchers to click on your site in the results quite so much as "Buffy's House of Sofas".
 Write with words
Write with wordsImages, flash, and other multimedia make for pretty web pages, but make sure your core messages are in text or use ALT text to provide textual descriptions of your multimedia. This is great for search engines, which are based on text: searchers enter search queries as word, after all. But it's also great for visitors, who may have images or Flash turned off in their browsers or might be using screen readers or mobile devices. You can also provide HTML versions of your multimedia-based pages (if you do that, be sure to block the multimedia versions from being indexed using a robots.txt file).
Make sure the text you're talking about is in your content
Visitors may not read your web site linearly like they would a newspaper article or book. Visitors may follow links from elsewhere on the web to any of your pages. Make sure that they have context for any page they're on. On your order page, don't just write "order now!" Write something like "Order your fluffy red sofa now!" But write it for people who will be reading your site. Don't try to cram as many words in as possible, thinking search engines can index more words that way. Think of your visitors. What are they going to be searching for? Is your site full of industry jargon when they'll be searching for you with more informal words?
As I wrote in that guest post on Matt Cutts' blog when I talked about hyphens and underscores:
You know what your site’s about, so it may seem completely obvious to you when you look at your home page. But ask someone else to take a look and don’t tell them anything about the site. What do they think your site is about?
Consider this text:
“We have hundreds of workshops and classes available. You can choose the workshop that is right for you. Spend an hour or a week in our relaxing facility.”
Will this site show up for searches for [cooking classes] or [wine tasting workshops] or even [classes in Seattle]? It may not be as obvious to visitors (and search engine bots) what your page is about as you think.
Along those same lines, does your content use words that people are searching for? Does your site text say “check out our homes for sale” when people are searching for [real estate in Boston]?
Make sure your pages are accessibleI know -- this post was supposed to be about writing content, not technical details. But visitors can't read your site if they can't access it. If the network is down or your server returns errors when someone tries to access the pages of your site, it's not just search engines who will have trouble. Fortunately, webmaster tools makes it easy. We'll let you know if we've had any trouble accessing any of the pages. We tell you the specific page we couldn't access and the exact error we got. These problems aren't always easy to fix, but we try to make them easy to find.